Jupyter et analyse de données avec Pandas
Prise en main de jupyter
Créez un répertoire notebooks sous votre répertoire de travail (supposé pg121):
mkdir pg121/notebooks
cd pg121/notebooks
Puis, depuis ce répertoire, lancer jupyter:
jupyter notebook
Votre navigateur devrait s’ouvrir à l’URL http://localhost:8888/.
Ouvrir un premier notebook
Téléchargez le fichier derivative.ipynb et placez-le dans votre répertoire pg121/notebooks.
Cliquez sur l’icône “Refresh the file browser” en forme de flèche circulaire, située en haut à droite de la fenêtre. Le fichier derivative.ipynb doit apparaître. Sélectionnez-le, puis appuyez sur le bouton “Open” (ou double-cliquez).
La page qui s’affiche est un notebook constitué de cellules. Certaines contiennent du texte formatté en markdown, d’autres contiennent du code python.
En double-cliquant sur une cellule markdown ou en tapant return quand la cellule est sélectionnée, vous faîtes appraître le code source. En pressant shift+return ou en cliquant sur l’icône “Run this cell and advance” en forme de flèche, le rendu apparaît à la place du code.
Les cellules de code python se comporte de la même façon, sauf que le résultat produit, s’il y en a un, apparaît sous la cellule et non pas à la place de celle-ci. Dans ce notebook, la toute derniere cellule de code génère un graphique qui s’affiche sous celle-ci.
Dans le menu “Run”:
- “Run selected cell and below” permet d’exécuter la cellule courante et les suivantes
- “Run All Cells” permet d’exécuter toutes les cellules du notebook.
Après avoir lu le contenu du notebook:
- vérifier que la dérivée calculée est bien la fonction cosinus, en ajoutant son tracé dans la dernière cellule de code (puis supprimer le tracé ajouté)
- calculer la dérivée de la fonction $x \mapsto \frac{1}{x}$ au lieu de $sin$. Vérifier que la dérivée obtenue est bien $x \mapsto -\frac{1}{x^2}$.
- en utilisant le code dans la 2ème cellule python, y définir une fonction
derivative(x,y)qui calcule et retourne le tuple(xd, yd). Puis utiliser cette fonction dans la troisième cellule python. - créer un fichier
derivative.pydanspg121/notebooks, et y déplacer la fonctionderivative(x, y). Remplacer le contenu de la deuxième cellule python parimport derivativepuis utiliser la fonctionderivative.derivative(x,y)dans la troisième cellule python - utilisez le menu “File / Save and Export Notebook As…” pour exporter votre travail au format de votre choix (markdown, PDF, …)
- fermer le notebook à l’aide du menu “File / Close and Shut Down Notebook”
Créer un notebook
Créer un nouveau notebook à l’aide du menu “File / New / Notebook” puis choisir le kernel Python3. Un nouvel onglet s’ouvre avec un notebook vide avec le titre “Untitled”.
- Renommer le notebook en “premier_notebook”
- Changer le type de la première cellule en “Markdown”
- Copier-coller le texte suivant dans la première cellule
# Python et Jupyter
Un notebook Jupyter est une suite de *cellules*: une cellule peut soit être du code à exécuter, soit du texte au format Markdown.
## Syntaxe Markdwon
Markdown permet d'écrire du texte en **gras**, en *italique*, de faire des [liens](https://python.org).
On peut faire des listes à puce:
- ligne 1
- ligne 2
- [ ] case à cocher
- [x] case cochée
Et numérotées:
1. d'abord
2. ensuite.
On peut insérer aussi des images:

Du code en ligne (`which python`) ou des fragments avec de la coloration syntaxique
```C
int main(int argc, char** argv) {
printf("Usage: %s\n", argv[0]);
return 1;
}
```
Et des tableaux
| Nom | Description |
| --- | ----------- |
| A | Texte |
| B | Data |
et des maths: $\sqrt{\sum_{i=1}^n x_i^2}$.
Voir https://www.markdownguide.org/cheat-sheet pour d'autres éliéments de la syntaxe.
- Exécuter cette cellule (shift+return)
- Changer le type de la nouvelle cellule en Markdown, puis y copier le contenu suivant
## Interface interactive de Jupyter ### Raccourcis utiles Pour passer en mode commande: esc. Voir la liste en tapant h (en mode commande) - m: mettre la cellule en mode Markdown - y: mettre la cellule en mode code - a: insérer une cellule au dessus - b: insérer une cellule au dessous - x: couper la cellule - v: coller la cellule en dessous - shift+return: exécuter la cellule et passer à la suivante
- Entrer les lignes de code suivantes dans des cellules successives en terminant chaque bloc par shift+return.
1+1
a = 3
a
print(a)
print('Hello world')
a
def double(x):
"""Retourne le double de x"""
return x*2
double(a)
?sum
?double
Rappel: modifier une cellule ne met pas à jour les autres cellules automatiquement!
Dans le menu “Run”:
- “Run selected cell and below” permet d’exécuter la cellule courante et les suivantes
- “Run All Cells” permet d’exécuter toutes les cellules du notebook. “Kernel > Restart & run all” permet de redémarrer l’interpréteur (kernel) et d’évaluer toutes les cellules
Autre fonctionnalités:
- auto-complétion
- faire référence au résultat d’une cellule
- exporter une version statique du notebook pour partager facilement le résultat
- exécuter une commande shell
1+2
_
_7
!ls -li
Fermer le notebook.
Prise en mains de pandas
Le module pandas permet de représenter et analyser des données 1-D nommées serie (type Series), ou 2D nommées data frame (type DataFrame).
Créer un nouveau notebook pandas_intro. Et importer le module pandas:
import pandas as pd
Créer une data frame ou une serie
Créer une serie:
s = pd.Series([1, 3, 5, np.nan, 6, 8])
s
type(s)
Une serie est un tableau unidimensionnel. Documentation via help(pd.Series) ou sur la page web.
Créer une data frame:
t = pd.DataFrame(np.random.randn(5, 4), columns=list('ABCD'))
t
Une data frame est un tableau bidimensionnel. Documentation via help(pd.DataFrame) ou la page web.
Créer une data frame à partir d’un fichier au format csv
!curl -fOL https://herbrete.zzz.bordeaux-inp.fr/pg121/countries.csv
df = pd.read_csv("countries.csv")
df
df.shape
Que représente l’information affichée dans le notebook?
Accès au colonnes
df.columns
df['NativeName']
type(_)
df[['NativeName', 'CallingCode']]
type(_)
Accès aux lignes
Sélection de la ligne par position entre 0 et N-1 où N est le nombre de lignes de la serie ou data frame:
df.iloc[1]
Pour un index non numérique:
u = pd.DataFrame([[1, 2],[3, 4]], index=list('ab'), columns=list('cd'))
u
u.loc['a']
type(_)
Indexation
Dans le fichier countries.csv, les entrées de la colonne Name sont uniques. Elle peut donc être utilisée comme index. On peut le spécifier au chargement:
df = pd.read_csv("countries.csv", index_col="Name")
df
Comparer avec l’affichage obtenu lors du chargement de countries.csv avec index par défaut.
df.index
df.loc["France"]
df.loc[["Germany", "France"]]
df.loc['France':'Germany'] # slicing
cc = df["CallingCode"]
cc
cc["France"]
Accès, requêtes, tri, statistiques
Comme avec numpy, on peut accéder à une valeur spécifique d’une serie ou d’une data frame par coordonnée “ligne, colonne”:
df.loc["Germany", "CallingCode"]
On peut rechercher des éléments d’une serie ou d’une data frame qui satisfont une certaines propriété:
df.query("CallingCode == 212")
Quel est le type de la valeur retournée?
big_cc = df.query("CallingCode / 100 >= 1")
big_cc
big_cc.shape
Tri sur une colonne donnée
sorted_big_cc = big_cc.sort_values("CallingCode") # retourne une copie
sorted_big_cc
big_cc
sorted_big_cc.iloc[-1] # dernière ligne
Accès à l’index
sorted_big_cc.index
sorted_big_cc.index[-1]
Statistiques
s = df["Population, 2019"]
s
s.describe() # statistiques élémentaires sur les valeurs numériques de la série
df.describe()
Représenter des données graphiquement
Comme précedemment, nous nous appuyons sur matplotlib pour représenter graphiquement des données. Documentation liée:
df.hist("Population, 2019")
df.hist("Population, 2019", bins="auto")
df.loc["France"]
import matplotlib.pyplot as plt
df.hist("Population, 2019", bins="auto")
plt.vlines(67055854, 0, 100, color="green")
plt.ylim(0,100)
Remplacer ci-dessus la valeur en dur 67055854 par la valeur correspondante obtenue depuis la data frame df.
Solution
df.hist("Population, 2019", bins="auto")
plt.vlines(df.loc['France', 'Population, 2019'], 0, 100, color="green")
plt.ylim(0,100)
df["Population, 2019"] >= 67055854
large = df[df["Population, 2019"] >= 67055854] # sélection avec masque, comme avec numpy
large
len(large)
large = large.sort_values("Population, 2019", ascending=False)
large
large.iloc[0]
large.plot.bar()
large.plot.bar(y="Population, 2019")
large.plot.bar(y="Population, 2019", figsize=(15,5))
Exercice: représentation du cours du bitcoin
Créer un nouveau notebook dans lequel vous réaliserez cet exercice.
!curl -fOL https://herbrete.zzz.bordeaux-inp.fr/pg121/bitcoin-usd.csv
bc = pd.read_csv("bitcoin-usd.csv")
bc
bc.plot(x="DATE", y="CBBTCUSD")
À l’aide de la documentation de DataFrame.plot et de matplotlib.pyplot.plot reproduire le graphique suivant à l’identique.
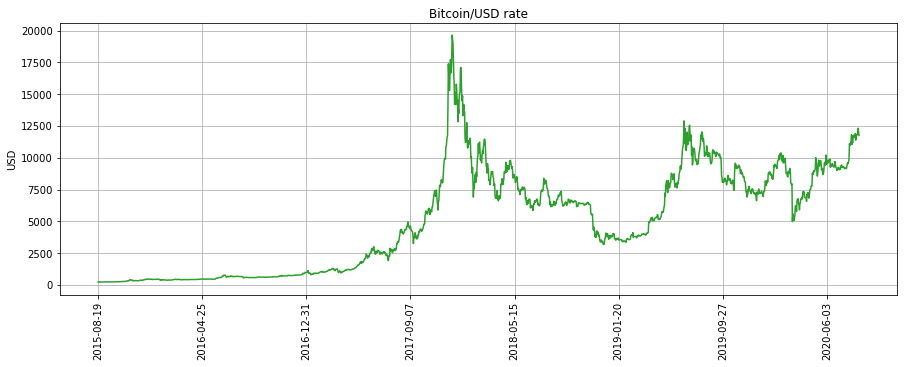
Solution
bc.plot(x="DATE", y="CBBTCUSD", color="green", grid=True,
legend=False, ylabel="USD", xlabel="", rot=90,
title="Bitcoin/USD rate",
figsize=(15,5))
Fermer le notebook.
Exercice: analyse des données des ventes de jeux vidéos
L’exercice consiste à analyser les données des ventes de jeux vidéos disponibles à l’URL: https://www.kaggle.com/datasets/gregorut/videogamesales. Les ventes sont jusqu’à 2016-2017, et sont exprimées en millions de copies (pré)vendues. Sauf indication contraire, les questions suivantes portent sur le nombre global de ventes Global_Sales.
Créer un nouveau notebook dans lequel vous réaliserez cet exercice.
Jeu le plus vendu
Ouvrir le fichier vgsales.csv en spécifiant la colonne Rank comme index. Il s’agit du classement par nombre de ventes dans le monde entier.
Quel est le jeu vidéo le plus vendu dans le monde?
Solution
vgsales = pd.read_csv("vgsales.csv", index_col="Rank")
vgsales.loc[1, "Name"]
Nombre d’éditeurs
En utilisant la méthode value_counts (cf. help(pd.DataFrame.value_counts)), compter le nombre d’éditeur (colonne Publisher) de jeux vidéos référencés dans la data frame.
Solution
len(vgsales.value_counts("Publisher"))
Titres les plus vendus dans la catégorie Action
Afficher les 5 titres les plus vendus par “Ubisoft” dans la catégorie “Action”(cf. help(pd.DataFrame.sort_values) et help(pd.DataFrame.head)). L’affichage se fera du titre le plus vendu à celui le moins vendu.
Solution
vgsales.query("Publisher == 'Ubisoft' and Genre == 'Action'").sort_values("Global_Sales", ascending=False).head()
Écrire une fonction action_games(d, publisher) qui retourne la data frame contenant les informations relatives aux jeux de Genre “Action” publiés par l’éditeur publisher dans d, triées par ordre décroissant sur la colonne Global_Sale.
Solution
def action_games(d, publisher):
return d.query("Publisher == '" + publisher + "' and Genre == 'Action'").sort_values("Global_Sales", ascending=False)
Puis utiliser cette fonction pour simplifier votre réponse à la question précédente, et obtenir l’information similaire pour l’éditeur “Nintendo”.
Solution
action_games(vgsales, 'Ubisoft').head()
action_games(vgsales, 'Nintendo').head()
Pourcentage des ventes par catégorie
Lister le nombre de jeux par genre en utilisant value_counts.
Solution
nb_genres = vgsales.value_counts("Genre")
Afficher les pourcentages de ventes de chaque catégorie sous la forme d’un diagramme circulaire comme-ci dessous. La méthode pd.DataFrame.plot.pie permet de dessiner de tels graphiques (voir sa documentation). Pour afficher les pourcentages, utiliser l’option autopct="%.1f%%".
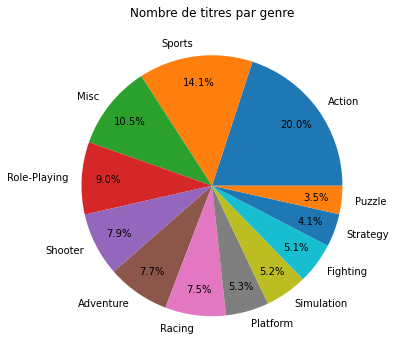
Solution
nb_genres.plot.pie(ylabel="", autopct="%.1f%%",
pctdistance=0.8, title="Nombre de titres par genre",
figsize=(6,6))
Jeux vendus à plus de 10 millions d’exemplaires
Obtenir la data frame des jeux vendus à plus de 10 millions d’exemplaires dans le monde.
Solution
vgsales.query("Global_Sales >= 10")
Visualiser les dix meilleures ventes par région
On peut représenter les ventes totales des dix meilleurs avec la commande suivante (où vgsales est le dataframe des données).
vgsales[:10].plot.bar(x="Name", y="Global_Sales")
À l’aide de la méthode bar, reproduire le graphique ci-dessous montrant la part des ventes en fonction de la région.
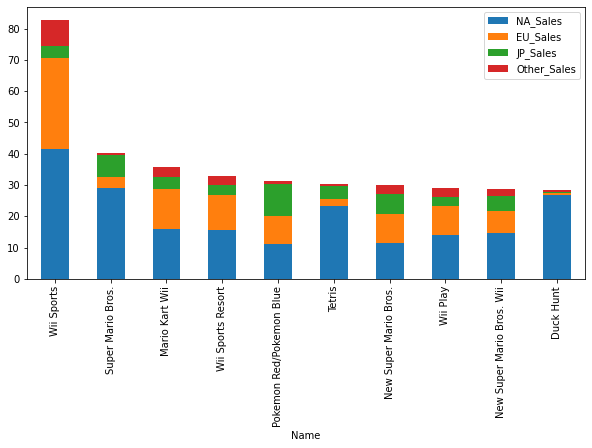
Solution
vgsales[:10].plot.bar(x="Name", y=["NA_Sales", "EU_Sales", "JP_Sales", "Other_Sales"], stacked=True, figsize=(10,5))
Exercice: analyse par sous groupe
Cet exercice peut être réalisé à la suite du précédent sur le même notebook, ou sur un nouveau notebook.
La méthode DataFrame.groupby permet de grouper plusieurs lignes d’un tableau selon leur valeur sur une ou plusieurs colonnes.
Exécuter la commande:
vgsales.groupby("Genre").sum()
La commande groupe les lignes par genre, tout en appliquant la fonction sum() aux valeurs regroupées.
Meilleurs vendeurs
Lister les 5 éditeurs (colonne Publisher) qui ont vendu le plus de titre au total.
Solution
vgsales.groupby("Publisher").sum().sort_values("Global_Sales", ascending=False)[:5]['Global_Sales']
Pourcentage des ventes par genre
Afficher un diagramme circulaire présentant les pourcentage de ventes par genre, comme celui-ci:
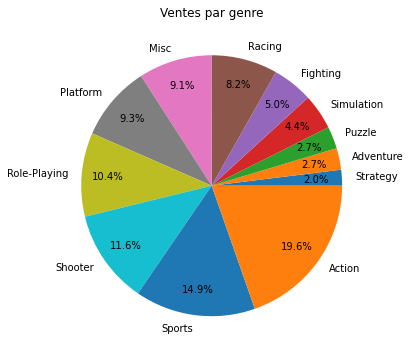
Solution
sales_genres = vgsales.groupby("Genre").sum()
sales_genres.plot.pie(y="Global_Sales", autopct="%.1f%%",
pctdistance=0.8, title="Ventes par genre",
figsize=(5,5))
Afficher les titres les plus vendus
Afficher les 5 titres les plus vendus par “Ubisoft” dans le genre “Action” toutes plateformes confondues.
Solution
vgsales.query('Publisher == "Ubisoft" and Genre == "Action"').groupby('Name').sum().sort_values('Global_Sales')[-5:]['Global_Sales']
Nombres de ventes par année de sortie
Calculer le nombre global de ventes pour Nintendo en fonction des années de sortie. Puis l’afficher sous forme graphique.
Solution
nintendo_by_year = vgsales.query("Publisher == 'Nintendo'").groupby('Year').sum()['Global_Sales']
nintendo_by_year.plot()
Données récentes
Garder uniquement les données des ventes depuis l’année 2000. Grouper par année (Year) et par plateforme (Platform) (il est possible de donner une liste à groupby), et faire la somme selon la colonne Global_Sales. Afficher le résultat.
Solution
g = vgsales.query("Year >= 2000.0").groupby(['Year', 'Platform'])['Global_Sales'].sum()
Généraliser les données avec unstack
Sur le nouveau tableau obtenu, appelez la méthode unstack() et afficher le résultat.
Solution
g_df = g.unstack()
g_df
Puis afficher le graphe à l’aide de la méthode plot().
Solution
g_df.plot()